what if i told you there is a system right now that can take natural language input so whatever description you want just make something up and it will take that text and turn it into a surprisingly realistic image of exactly what you described so you type an astronaut riding a horse and it spits out a brand new image of an astronaut riding a horse you type teddy bears shopping for groceries and boom there’s an image of teddy bear shopping for groceries you type a bowl of soup that is a portal to another dimension and boom my god it’s a bowl of soup that’s a portal to another dimension and it’s not just one it actually spits out 10 different versions across a spectrum of variation in any art style you want you name it and it can draw it so what is happening here how does it work and what happens if i try so first things first yes this does exist this is a real thing it’s called dolly 2 and it’s an ai research project by a company called openai one of many elon musk co-founded companies at this point and so the purpose of this ai specifically is to create original realistic images and art from a text description this is aditya ramesh a researcher and co-creator of dolly one and dolly two he’s easily the most qualified person to explain what’s
happening here um so the way w1 generates images dolly one generates an image starting from the top left and moving industrial order row viral so diffusion works completely differently the way diffusion works is we train a model to reverse a corruption process that’s applied to clean images so it’s kind of hard to wrap your head around but basically there’s two main ai technologies behind dolly two they’re called clip and diffusion so clip is the part that’s matching images to text and basically uses that match to train the computer to understand concepts in images so it can generate new images of the same concepts so when i asked it for an astronaut riding a horse for example it’s not just making a mosaic of images it found online it knows the idea of what an astronaut is it knows what the concept of writing means it knows what a horse is and maybe most impressively it knows what’s an aesthetically pleasing image to humans so then it can create a completely new visual version of this idea that hasn’t existed before now clip doesn’t really have the ability to do the pretty high resolution images all by itself it’s just more generating the gist of an image based on those concepts so that is where diffusion comes in so diffusion is super
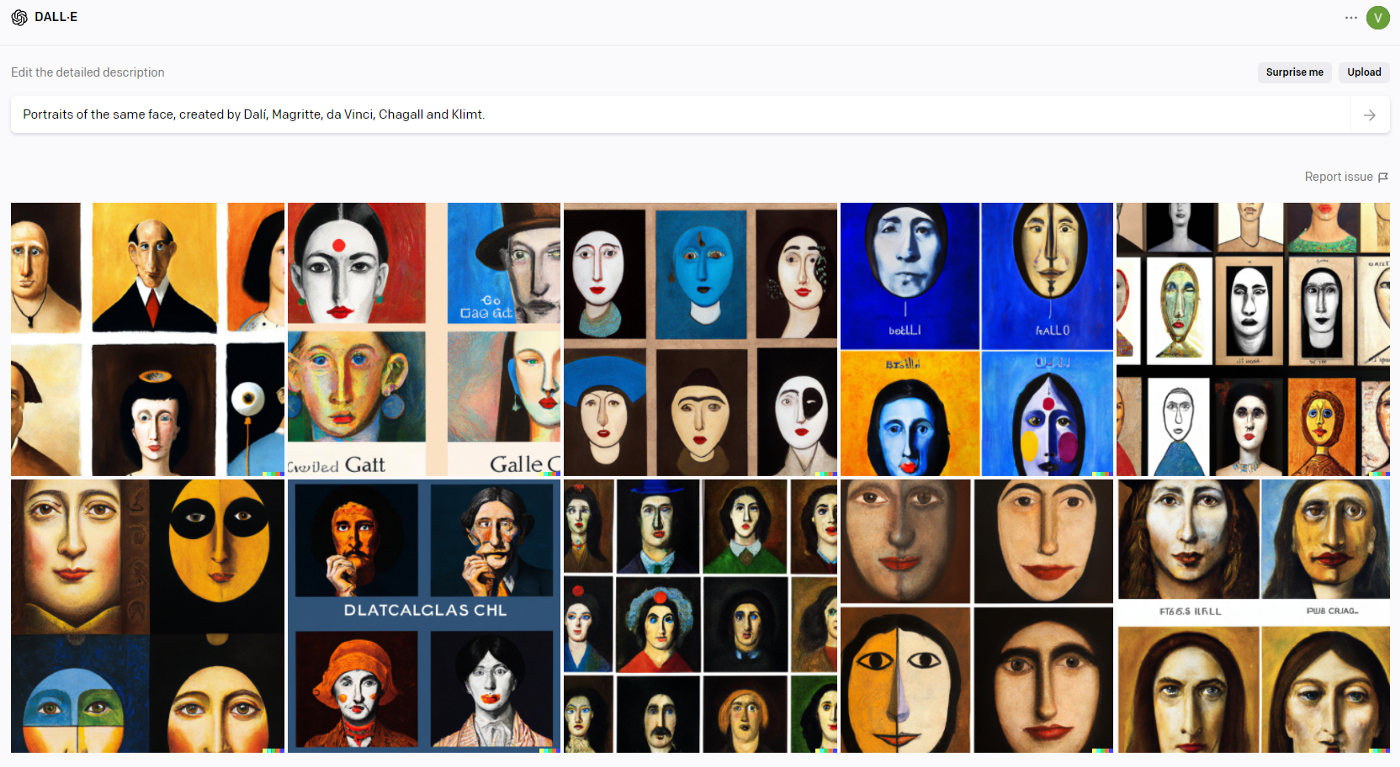
impressive basically by teaching a computer to corrupt an image by adding gaussian noise it can then learn to uncorrupt or enhance an image by removing that noise it’s kind of like step one draw the circle step two draw the rest of the owl so i don’t know if you’ve ever seen this website called this person does not exist.com but if you haven’t you should check it out it shows you a surprisingly realistic image of a face but as you might have guessed this person does not exist it’s not a real face it’s actually using ai to look at thousands of faces and then generate a new face with that information that is shockingly realistic but it turns out is not a real human so dolly dolly 2 is like a way more advanced generalized version of that for anything so when you open it up it’s literally just a blank search text box where you can type in whatever you want to create now of course as you can probably imagine with all these concerns and possibilities this isn’t just a tool that’s available to the public it’s not like anyone can use it openai has kept this mostly behind closed doors to a very small hand-selected group
of people but for a day they gave me the keys and i was able to generate whatever i want which of course means i had to ask it to finally reveal to us what the long-awaited apple car would look like i mean this is an opportunity unlike any other so i typed it in i waited my 10 seconds with great breath and then the secret was finally unveiled oh right of course i don’t know why i expected anything different but for real okay so the open ai team was kind enough to allow me to feed dolly 2 whatever i want so i decided to start pretty simple and then get a little bit more complex as we go so a blue apple and a bowl of oranges so okay these are good these are actually i mean that was extremely easy but the sharpness the realism the lighting even to just create these brand new out of nothing there is so much detail in this one it’s kind of hard to believe it isn’t real okay an elderly kangaroo i mean i don’t know what i expected specifically an elderly kangaroo to look like i guess maybe i pictured gray hair or something but i buy it i mean the fact that it’s again it’s not a real photo but it looks like a real photo of an elderly kangaroo that is very impressive a wise elephant
staring at the moon at night whoa okay so that is definitely a wise elephant he or she is in fact staring at the moon and it is definitely at night it’s not bad the moon does look a little bit wonky if you if you look a little bit closer on some of these it’s not perfect but the elephant is very real looking okay let’s get a little more specific here a teddy bear doing surgery on a grape in the style of a 1990s cartoon oh my god look at these cartoons sometimes it misses totally understandable also it seems to have chosen scissors instead of maybe a more realistic actual surgery i’ll get to why in a minute but the facial expressions the feet and everything i mean that is a teddy bear doing surgery on a grape all right this one’s from mac the studio dog a cooker hunch i’m pronouncing that wrong using a camera on a movie set wow that is okay if you couldn’t already tell that is the name of the dog breed and the closer you inspect each individual image the more the photo realism part
kind of falls apart which maybe isn’t shocking because this is kind of a crazy thing to have a picture of but the detail in the dog breed and it actually using the camera in the pictures is crazy good i wonder if we could post that to mac’s instagram if anybody would notice that it’s not a real picture i’d probably figure it out all right a robot woman guarding a wall of computers wow okay so so many interesting details and decisions being made in these images so the word guarding implies a bit of a pose and there’s a couple different guarding poses here but that’s cool the computers for the most part are also pretty convincing if you don’t zoom in too much and also it’s interesting that none of the walls of computers go all the way up to the ceiling either which is cool but that is definitely a robot woman guarding that wall of computers alright what if we go a tiger discovering the lost city of atlantis wow okay these are more of an art style probably because one there won’t be any like photo realistic reference images of the lost city of atlantis so i imagine it’ll look better this way and two this is a crazy image to create so with each of these they’re great
without zooming in and pixel peeping and they very much accomplish the goal of illustrating a tiger discovering atlantis like i asked the crazy part here though to me is how much imagination it’s using like i’m actually getting more than what i asked for the facial expressions poses orientation of things reflections even the accurate lighting in shadows is crazy like i asked for a tiger discovering atlantis here but it’s decided to add trees and birds and a moon all by itself all right here we go here we go a painting inspired by the mona lisa of a goat taking pictures with an ipad i this is my new favorite thing you you can really just go off the rails with complexity and it just gets them right almost all of these goats have hands too which is hilarious but the drawings themselves have actually also stayed true to the theme it’s a painting in the style of the mona lisa and the tablets are all you know varying levels of convincing ipads wow i’m going to put these all on
twitter by the way in like one big thread plus a few extras if they don’t make it into the video so definitely hit the link below if you want to see those but last but not least a cyclops riding a tractor listening to airpods in the style of the simpsons i mean come on maybe it’s not a perfect cyclops and it is interesting that it’s chosen over the ear headphones for all of the headphones and not you know airpod earbuds but i feel like there’s nothing this can’t do this is one of those ai tools that’s so good that it almost brings up more questions than it answers like why does a tool like this even exist in the first place well dolly 2 is a research project not a customer product and open ai’s goal is to create good safe general ai which is really hard like there are a lot of really really good task specific ai systems that’ll do things from like detecting cancer in x-rays to self-driving cars that navigate the streets or just sharpening photos in photoshop but the whole general ai thing which needs a ton of information to be able to navigate a ton of
different situations is a whole other challenge i mean if you think like tesla robot walking around the earth completing tasks for you like that’s the level we’re talking about here and so being able to recognize objects and images and associate them very quickly and accurately is a big part of that now are there things that dolly doesn’t do well yes actually there are both some intentional and some unintentional shortcomings of dolly 2 as it exists right now so on the intended side uh the library of images that dolly references is massive but it doesn’t have any images of adult content or illegal activity or violence so it doesn’t create images with that stuff in it makes sense that’s probably why we got scissors in the teddy bear’s hand instead of a knife because that’s the next closest association the ai was able to make for that surgery and you also can’t ask for imagery of specific identities of people so you can ask for man robbing a bank but you can’t ask for marquez
brownlee robbing a bank as curious as i am about what type of image that would spit out you can’t that would be dangerous for obvious reasons but also dolly 2 is known to have some quirks so one of them is it doesn’t do very well specifically with variable binding or what basically will happen when you ask for relative position of objects in an image so if i ask for a red cube on top of a blue cube it might just give you a blue cube on top of a red cube and we actually saw this in one of the images i got back for a blue apple and a bowl of oranges well right there that’s clearly an orange in a bowl of blue apples which is kind of funny and it also for whatever reason doesn’t do written text well so sometimes it can give you certain letters but if you ask it for like a sign that says a certain word it’ll almost never actually give you that there’s actually a pretty hilarious twitter thread of someone asking dolly for signs with certain things over and over again just to see what random text it spits out which is also pretty funny but this is the type of stuff that i’ll be working on for dolly 3 and for future versions as you can imagine but it’s funny with every shortcoming they found there was also an equally awesome accidental upside they discovered too like this diffusion
method can also transform images so you can take an existing image and run the model over and over to push it more and more towards any prompt you want so you can take this plain jacket for example and slowly turn it into a jackson pollock painting or take this picture of a cat and slowly turn it into a samurai master or take a picture of tech a piece of tech and slowly un-modernize it over and over like look what it does to this iphone it turns it back into an older and older phone it’s modifying existing images based on other existing concepts it’s it’s kind of sick so is this going to be taking people’s jobs well lucky for you if you want the exact answer to that question that’s literally the concept we attacked with the new studio video so i’ll link it below the like button if you want to watch it but we pit dolly 2 up against tim who is the graphic designer here at the mkbhd studio where their jobs are kind of basically the same thing it’s to turn the words coming out of my mouth into a good-looking image spoiler alert if you give tim
enough time he’ll make something better but in 10 seconds dolly is able to spit out a bunch of different variations and while the images might be a bit fuzzy around the edges or have weird text or fall apart when you zoom in on faces or hands or objects this tool as presently constructed is amazing for brainstorming ideas and concepts and things that would normally take much longer to create is truly an amazing side effect of the development of this ai that it’s able to make this tool where the images that it spits out aren’t necessarily supposed to be finished final pieces of work but they are a great starting point for making stuff later that’s actually exactly what we did with this video’s thumbnail which started off as an image generated by dolly where it was told to make a robot hand drawing so i have no doubt that there will be versions of dolly in the future that make even higher resolution and more photorealistic images and then even better like quick animations and then video clips and then whole movies even all on our way to this general ai goal that we’re working towards what a time to be alive thanks for watching catch you guys the next one peace
Read More: Atomos Ninja V great recorder, but average monitor | SmallHD Focus 5 Comparison